Abstract
La convergenza tra informatica, archivistica e diritto nella gestione degli archivi ha il traguardo di preservare e rendere fruibili le informazioni, rispettando standard tecnici, legali e di gestione dei dati. La gestione degli archivi – quelli della Pubblica Amministrazione o quelli più tradizionalmente informatici – richiede un approccio multidisciplinare a cui contribuiscono molti saperi. Le strade per la convergenza di saperi – però – possono presentare difficoltà con livelli differenti che, a loro volta, vanno gestiti negli insiemi di norme con visione e, al tempo stesso, con attenzione ai particolari. La buona notizia è che la complessità può essere ridotta e rappresentata con diagrammi e grafici di semplice lettura. Dopo una breve introduzione, vengono presentati tre esempi di convergenza: uno non scontato, uno che sembra divergente, uno che parla di disaggregazione e riaggregazione. Ogni esempio è corredato da un diagramma.
Questa breve esplorazione può cominciare con gli archivi della Pubblica Amministrazione perché sono soggetti a diverse regole e assommano in sé sia la tradizione archivistica dell’Europa continentale, sia gli sviluppi normativi e tecnici degli ultimi decenni.
La complessità degli archivi pubblici
Sugli archivi pubblici si addensano insiemi di saperi molto distanti che vanno dall’archivistica all’organizzazione e alla logistica, alla gestione documentale, al diritto amministrativo, alla necessaria protezione di diritti e libertà, alla protezione dei beni culturali, all’informatica, al valore storico e giuridico di quanto di quanto prodotto a livello documentale dall’Amministrazione.
Il Codice dei Beni Culturali comprende gli archivi della Pubblica Amministrazione tra i beni culturali ab origine (Dlgs.42/2004 art.10.2.b) rendendoli meritevoli di protezione dallo Stato. Al tempo stesso, il Regolamento eIDAS definisce i documenti informatici in modo molto ampio come “qualsiasi contenuto conservato in forma elettronica, in particolare testo o registrazione sonora, visiva o audiovisiva” (Regolamento UE 2014/910 art.3.35).
Pertanto, prima di firme e metadati, prima dei requisiti di immodificabilità, integrità e autenticità garantiti dal sistema di gestione documentale, prima della conservazione a norma, prima ancora dell’adozione di un Manuale di Gestione Documentale e Protocollo, un archivio della Pubblica Amministrazione può comprendere “materiale” informatico di ogni tipo.
Una complessità che va gestita con attenzione e cura e che può essere rappresentata graficamente come punto di incontro di affluenti molto diversi come nel diagramma che segue.
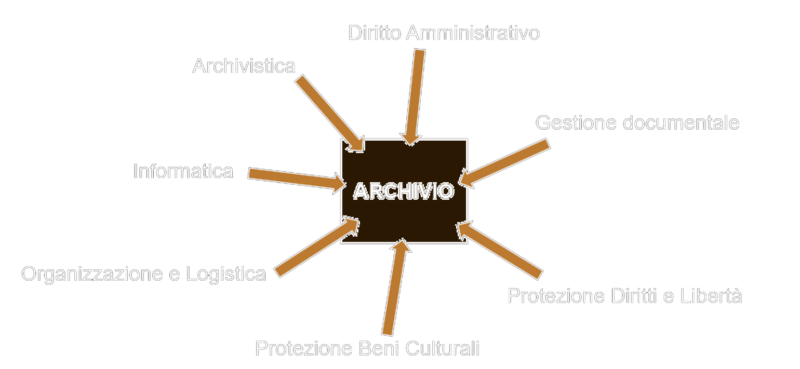
Fig. 1 – Una rappresentazione di convergenza dei saperi nella gestione degli archivi delle Pubbliche Amministrazioni. L’archivio come punto di arrivo di differenti saperi. Grafico dell’autore.
Non tutto è sempre così semplice e scontato, altre forme di convergenza possono seguire percorsi meno lineari e naturali. È il caso del modello di convergenza di Nicholas Negroponte illustrato nel prossimo paragrafo.
Convergenza non scontata: il modello di Negroponte
L’informatica, la produzione massiva di documenti e di contenuti audio/video contribuiscono ad alimentare archivi. Questi tre ambiti oggi sono sovrapposti e costituiscono una forma di convergenza che chiunque ritiene scontata ma negli anni ‘70 pochi erano stati in grado di presagire. Uno dei pochi, sicuramente il più famoso e acuto, era stato Nicholas Negroponte.
Con due semplici diagrammi di Venn, Negroponte nel 1978 mostrava tre ambiti industriali che cominciavano appena a toccarsi: film e televisione, stampa e pubblicazioni, informatica. Tre settori con origini diverse e tradizioni separate che nel giro di due decenni si sarebbero sovrapposti essenzialmente per mezzo delle tecnologie dell’informazione e della comunicazione.
L’intersezione delle tre aree sarebbe stata quella di maggior crescita e, nel corso di pochi anni, avrebbe dominato tutte le altre.
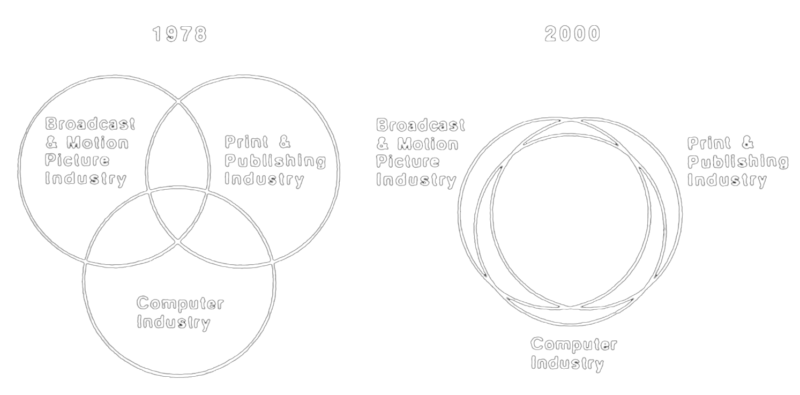
Fig. 2 – Diagramma della convergenza di Nicholas Negroponte. Le industrie televisiva, editoria e informatica, nel giro di 22 anni, sarebbero confluite verso un unico settore onnicomprensivo. – Fonte dell’immagine: Stewart Brand, “The Media Lab – Inventing the Future at MIT”, Viking Penguin Inc., 1987.
Negroponte era (ed è ancora) un ricercatore visionario e trascinatore, ma anche una persona molto attenta ai particolari e con interessi e connessioni con altri sistemi di sapere. Con questa visione aveva fondato il Media Lab presso il MIT. Il Media Lab fin da principio era stato concepito come fucina di idee con molte radici e con l’ambizione di definire le tecnologie informatiche e i comportamenti collettivi del futuro. Previsioni in gran parte riuscite.
Dal Media Lab erano uscite molte idee, molte proposte e molte previsioni raccolte successivamente in un libro scritto da Stewart Brand, uno dei migliori collaboratori di Negroponte. Il libro del 1987, di grande chiarezza e lungimiranza, a distanza di quasi quattro decenni può permettersi di essere ancora venduto in formato cartaceo. Un libro invecchiato decisamente bene.
In anni più recenti Negroponte è diventato noto al grande pubblico con il libro “Essere digitali” (la versione originale è “Being Digital”, Alfred A. Knopf, Inc., 1995; l’ultima edizione in italiano è “Essere Digitali”, Sperling & Kupfer, 2004). Si tratta tuttora di un libro godibile e attuale in cui, ancora una volta – se si potesse diremmo “con senso estetico intellettuale” – sono raggruppate connessioni non scontate, l’alto e il basso, la visione e l’operatività. L’ultima iniziativa nota al grande pubblico, “One Laptop for Child”, è forse l’unica di non grande impatto, ma questo non intacca la figura di chi ha mostrato convergenza dove altri non la vedevano e di indicare una strada da percorrere. Quella che effettivamente tutti hanno seguito.
Le informazioni di un archivio sono organizzate con strutturazione logica e chiara categorizzazione, ma per poterle utilizzare, la pulizia nell’organizzazione del dato non è sufficiente. È necessario che anche gli strumenti da utilizzare siano comodi e intuitivi.
Nel paragrafo successivo si vedrà come l’interazione con le macchine per lavorare sulle informazioni abbia una radice comune forse poco conosciuta.
Convergenza che sembra divergenza: le interfacce grafiche per la gestione delle informazioni
I percorsi di innovazione possono essere non lineari. Oggi per chiunque è scontato usare i computer in un certo modo. Non è sempre stato così, in decenni passati i computer servivano per elaborare dati e informazioni e l’interazione uomo-macchina era scomoda e fuori dalla portata delle persone comuni.
Gli studi sull’interazione in senso moderno coi computer erano cominciati a livello teorico quando queste macchine non esistevano neppure. L’antesignano e precursore era stato il Memex, troncamento delle parole Memory Expansion (espansione della memoria).
Era stato concepito nel 1945 da Vannevar Bush, un ricercatore e – ancora una volta – una persona capace di personificare la multidimensionalità del sapere e, al tempo stesso, con ruoli di alto livello in alcuni dei più importanti sviluppi tecnologici militari del suo tempo tra cui lo sviluppo del radar e della prima bomba atomica.
Le fonti che lo riguardano sono corpose ma merita almeno la lettura dell’articolo seminale sul Memex: Vannevar Bush, “As we may think”, The Atlantic, July 1945 Issue. In questo scritto, Bush, da capo del dipartimento americano per le nuove tecnologie belliche, collega le tecnologie del suo tempo all’espansione della mente e della cultura e, come esempio emblematico, esordisce con gli studi di Gregor Mendel sull’ereditarietà. Le conclusioni di Mendel non erano giunte a quei pochi in grado di coglierne l’importanza e di estenderle a causa dell’assenza di tecnologie, programmi e ingegno e – con un’ottica più moderna – anche di un ecosistema di mercati e investimenti.
Il Memex era stato concepito teoricamente come una macchina in grado di trattare il sapere di libri, documenti e giornali (cartacei, ovviamente) e, soprattutto di collegare i concetti e permettere il recupero delle informazioni tramite collegamenti interni: una chiara anticipazione del Web e dell’ipertesto ma anche di come il concetto di vincolo archivistico avrebbe potuto essere declinato in modo molto fluido.
Il Memex avrebbe dovuto essere una macchina elettromeccanica basata su microfilm, ma a causa dei limiti tecnologici del tempo, non era stata realmente sviluppata.
Accanto a questo ruolo sull’organizzazione delle informazioni, il Memex occupa anche il ruolo di precursore delle moderne forme di interazione coi computer moderni basate su mouse, finestre, menu etc. La strada che dal Memex e porta agli insiemi mouse-finestre non è stata ordinata. I percorsi sono stati molti, intrecciati, né sempre linearmente convergenti né sempre divergenti ma – anzi – spesso hanno preso direzioni inaspettate.
Il risultato finale, però, è che, pur nella complessità della sua evoluzione, chiunque oggi usa mouse e finestre, in qualunque ambiente e, pertanto, i percorsi possono essere disordinati ma alla fine c’è stata forte convergenza. Il grafico che meglio illustra questi percorsi è il “Bushy Tree”, l’albero frondoso dei sistemi di gestione delle informazioni e delle interfacce grafiche utente.

Fig. 3 – Nell’”albero frondoso” dei sistemi di gestione delle informazioni e di interazione con le macchine il Memex occupa la posizione di vertice, antesignano di tutte le tecnologie successive. – Fonte dell’immagine: John Radant e Bruce Damer, “The Bushy Tree Diagram”, 2001. Si tratta di uno sviluppo di una precedente versione degli anni ‘80. Il diagramma è molto diffuso ma – un po’ paradossalmente in questo contesto – non è possibile reperire il sito che l’aveva inizialmente diffuso.
Questo diagramma evidenzia anche un aspetto non scontato del mondo dell’informatica personale. Contrariamente all’idea comune, l’interfaccia grafica del primo Apple Macintosh del 1984 era basata su finestre e mouse, ma non era stata veramente la prima. Era stata preceduta dallo Star 8010, un computer sviluppato da Xerox negli anni ‘70, un nobile pioniere oggi del tutto dimenticato.
Se l’interazione uomo-macchina per la gestione delle informazioni ha raggiunto da molti anni la stabilità dei sistemi basati su finestre e mouse, possiamo chiederci se sia avvenuta o stia avvenendo una cosa simile per l’organizzazione delle informazioni contenute negli archivi. Cioè il tema del prossimo paragrafo.
Convergenza e complessità: il modello OAIS
Come ultimo esempio di saperi che convergono in modo inaspettato può essere preso il modello OAIS (Open Archival Information System). Si tratta di un modello per la gestione e la conservazione a lungo termine di documenti digitali.
In questa sede merita ricordare che il modello OAIS (standard internazionale ISO 14721) unito allo standard Sincro (standard italiano UNI 11386) è centrale per la conservazione a norma in Italia. Ai sensi di eIDAS 2 (Regolamento Ue 2024/1183 che integra il 2014/910), l’impostazione italiana verrà presa come modello per l’e-Archiving nei Paesi dell’Unione.Non era scontato visto che i modelli possibili sono almeno nove.
Semplificando, le aggregazioni archivistiche e unità documentarie, entrano – cioè vengono versate (da un producer) dentro il modello e possono successivamente essere esibite (a un consumer).
Internamente – però – le informazioni vengono smembrate e ricomposte in modi molto lontani dalla concezione classica di un archivio come complesso organizzato di aggregazioni documentarie. Le informazioni perdono la loro struttura d’archivio in quanto vengono dapprima aggregate in lotti e poi disaggregate in pacchetti arricchiti da informazioni utili al processo di conservazione. L’intero processo è gestito da più unità funzionali tra cui le due più prevedibili, cioè quella che accoglie le informazioni all’ingresso (ingest) e quella che le esibisce (access). C’è poi un’unità che memorizza (archival storage) e un’altra che gestisce gli indici (data management) di quanto memorizzato.
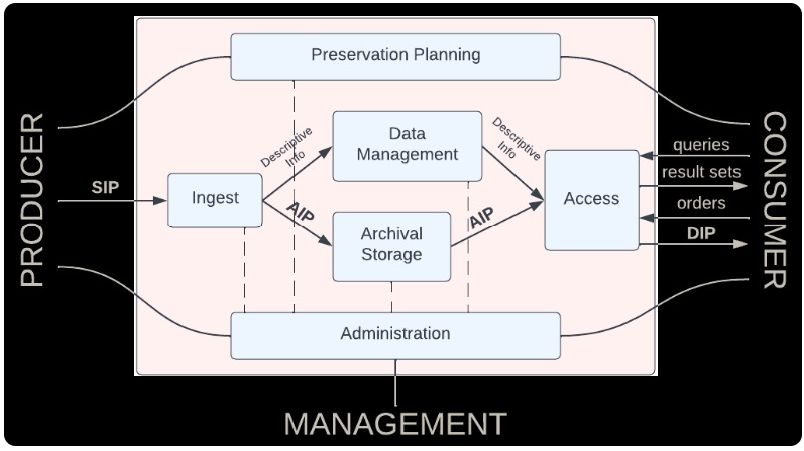
Fig. 4 – Nel modello OAIS i documenti e le informazioni vengono versati dal producer all’unità ingest a sinistra. A destra vengono esibiti dall’unità access al consumer. All’interno vengono sdoppiati tra l’unità archival storage che si occupa dell’archiviazione in senso stretto e l’unità data management che gestisce gli indici. – Fonte dell’immagine: Chelakis Konstantinos Marios, “Creating an Open Archival Information System compliant archive for CERN”, tesi di laurea presso Aristotle University of Thessaloniki, 2022.
Separando il contenuto archivistico dai suoi indici, il modello separa il sapere dal sapere dei saperi e, tuttavia, attraverso le norme sul valore giuridico della conservazione realizza la fase di archivio di deposito e potenzialmente anche quella di archivio storico in un modo lontano dalla concezione caratteristica di un archivio.
Conclusioni
In un preciso ambito, quello degli archivi, sono stati presentati tre esempi che suggeriscono come immaginare soluzioni per situazioni complesse – o banalmente solo far funzionare le soluzioni esistenti – richieda il giusto equilibrio tra una visione multilivello, una conoscenza dei sistemi di regole e norme, una commistione tra saperi pratici e innovativi. Il tutto unito anche – perchè no – a un certo senso estetico.
Le strade che convergono verso soluzioni possono essere lineari o accidentate e il lavoro intellettuale di chi è chiamato a risolvere è quello di annodare numerosi aspetti magari molto distanti per ottenere le vie d’uscita più semplici e attuabili nel proprio contesto.
In questo senso la capacità di visualizzare e di risolvere i problemi reali – o anche prima che vengano immaginati – richiede un’autentica intelligenza artigianale.
PAROLE CHIAVE: archivi / convergenza / diagrammi / informatica / informazioni / OAIS / Pubblica Amministrazione
Tutti i contenuti presenti in questa rivista sono riservati. La riproduzione è vietata salvo esplicita richiesta e approvazione da parte dell’editore Digitalaw Srl.
Le foto sono di proprietà di Marcello Moscara e sono coperte dal diritto d’autore.